Design für die Cloud
Im April 2012 besuchte ich die JAX in Mainz. Einer der Vorträge der mir dort am besten gefallen hat, war ein Vortrag von Mathias Meyer (http://www.paperplanes.de/) zum Thema „Design for Cloud“. Worum ging es in diesem Vortrag? Es ging darum, auf wichtige Aspekte hinzuweisen die zu beachten sind, wenn man Applikationen in der Cloud anbieten möchte.
Bevor die Aspekte beleuchtet werden, ein kurzes Glossar:
Region: Als Region wird ein geographisches Gebiet bezeichnet. Am Beispiel von Amazon’s EC2 Service sind dies Ost- und Westküste der USA, Europa, Singapur, Japan sowie Südamerika.
Datacenter: Ein Datacenter ist nicht der englische Begriff für ein Rechenzentrum. Die Summe aller Datacenter, stellen die Cloud dar.
Instanz: Eine Instanz beschreibt festgelegte Eigenschaften wie Speicher, CPU und Harddisk. Je größer eine Instanz ist, desto leistungsstärker ist sie. Eine Instanz wird beispielsweise bei EC2 (der Clouddienst von Amazon) nach Stunden abgerechnet. Auf einer Instanz wiederum läuft die Applikation in der Cloud. Eine Übersicht von Instanztypen findet sich hier: (http://aws.amazon.com/de/ec2/instance-types/).
Hier eine Übersicht über den Zusammenhang zwischen Region, Data Center, Instanz:
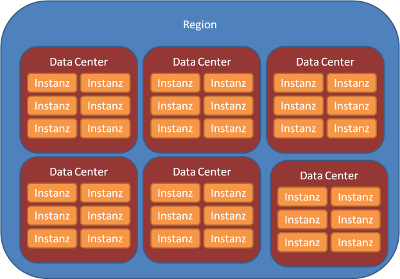
Es folgen nun die Aspekte / Fragen die für das Betreiben einer Applikation in der Cloud bedacht werden sollten:
Du bist nicht alleine: In einer Cloud ist man nie alleine. Man teilt sich die begrenzten Ressourcen (Prozessor, Netzwerkkapazitäten, Festplatte) mit einer theoretisch unendlichen Anzahl von Applikationen. Je mehr Applikationen es gibt, desto weniger Leistung steht einem selber zur Verfügung.
Was kaputt gehen kann, wird kaputt gehen: Wir können zwar Hardware emulieren, aber die Hardware, auf der die emulierte Hardware läuft, können wir nicht emulieren. Maschinen können nicht ewig funktionieren. Das ist ein Fakt. Alles andere wäre ein Perpetuum Mobile und somit nicht möglich.
Fehlerhafte Instanzen: Niemand ist davor gefeit, das die eigene Instanz abstürzen kann. Es bleibt dann nicht anderes übrig als die Instanz zu beenden und erneut hochzufahren.
Datacenter können ausfallen: Auch Datacenter können ausfallen; sei es durch einen Blitzeinschlag, Stromausfall oder jemand hat den Stecker gezogen hat weil es zu laut war. Um ein komplettes Datacenter wieder hochzufahren kann es mehrere Tage dauern. In diese Zeit fällt die Fehleranalyse & Fehlerbehandlung.
Datenverlust: Was passiert mit meinen Daten, wenn die Instanzen ausfallen? Kundendaten dürfen unter gar keinen Umständen verloren gehen! Jede noch so tolle Applikation ist nutzlos, wenn es sich die Daten, auf die sie angewiesen ist, nicht merken kann.
Performance: Wie schnell muss meine Anwendung reagieren können? Wieviele Nutzer sind zu erwarten? Ist die Belastung konstant hoch? Gibt es Lastspitzen?
Schwachstellen im Code: An welchen Stellen kann meine Applikation den Dienst verweigern? Wo sind neuralgische Punkte? Was kann alles ausfallen?
Kosten: Das Betreiben einer Anwendung in der Wolke kostet Geld. Wieviel sollte ich ausgeben?
Wie kann den zuvor genannten Herausforderungen begegnet werden?
Nutzung von verschiedenen Regionen und verschiedenen Datacentern: Wenn das Budget es zulässt, sollten die Anwendungen auf soviele Regionen und Rechenzentren verteilt werden wie nötig und möglich. Es wahrscheinlicher das ein komplettes Rechenzentrum / Region ausfällt (21. April 2011: Das Datacenter an der Ostküste der USA fiel komplett; 06. August 2011: Amazon’s EC2 im Data Center Irland fiel aus) als das alle Regionen gleichzeitig ausfallen. Je weiter verbreitet meine Anwendung auf dem Globus ist, desto geringer die Chance dass sie global nicht erreichbar ist. Natürlich gibt es hier den Nachteil von höheren Latenzzeiten, aber eine langsame Anwendung ist immer noch besser als eine nicht erreichbare Anwendung.
Keine Angst vor dem Versagen: In der Menschheitsgeschichte hat es schon viele Beispiele gegeben, wo es sich gezeigt hat, dass Angst von etwas Unbekanntem herrührt. Man muss sich der Gefahr stellen! Wie kann sich der der Angst gestellt werden? In dem man genau den negativen Fall testet: Wie reagiert meine Anwendungen bei höheren Latenzzeiten? Was passiert wenn ich einige Instanzen abschalte? Wird dann automatisch auf andere Rechenzentren gewechselt? Habe ich den Fall überhaupt bedacht? Weiß ich wie und wie schnell in andere Datacenter deployed werden kann? Diese Fragen muss man für sich selbst beantworten können! Nicht der Dienstleister muss schuld sein; meist ist man es selber wenn die vorhergehenden Fragen nicht gestellt bzw. nicht beantwortet hat.
Replikation: Die Daten die ein Kunde während der Benutzung einer Applikation gespeichert müssen repliziert werden. Was nützen mir die Daten wenn sie in Datacenter A liegen, die Anwendung aber plötzlich auf Datacenter B läuft? Weiterhin: Eine Instanz hochzufahren ist einfacher als Daten neu einzuspielen! Es muss sichergestellt werden, dass die Daten immer und überall verfügbar sind; möglichst mit dem gleichen Aktualitätsgrad.
Kosten: Die Kosten sind immer ein sensitives Thema. Um sich diesem Thema zu nähern sollten folgende Fragen bedacht werden: Kann ich es mir leisten nicht verfügbar zu sein? Wie wichtig ist die Hochverfügbarkeit meiner Anwendung? Eine falsche Entscheidung kann nicht nur Geld kosten…
Datenverlust: Kundendaten dürfen unter gar keinen Umständen verloren gehen. Jede noch so tolle Applikation ist nutzlos wenn es sich die Daten nicht merken kann. Wie kann ich also Datenverlust vermeiden? Man sollte seine Daten niemals in einer Instanz speichern. Ist die Instanz weg, so sind es auch meine Daten. Hier kann es helfen, seine Daten an anderen Orten als in der Cloud zu speichern. Diese Daten könnten dann beispielsweise mit Hilfe von Services verfügbar gemacht werden.
Performance: Reagiert eine Anwendung zu langsam? Sind die Antwortzeiten zu hoch? Hier kann schon alleine die Wahl einer größeren Instanz helfen. Je größer desto besser (siehe Instanztypen hier: http://aws.amazon.com/de/ec2/instance-types/. Auch über die Verwendung von Caches muss nachgedacht werden. Hilft auch die Verwendungen von größeren Instanzen nicht, so muss auch der eigene Code untersucht, wo möglich Flaschenhälse sich aufgetan haben.
Analyse von Schwachstellen: Es muss sich bei an dieser Stelle gefragt werden, wo kann die Anwendung brechen? Es sind mindestens die Stellen im Code wo Verbindungen zu Drittsystemen. Niemand kann garantieren die anderen Systeme immer zur Verfügung stehen. Was aber sichergestellt werden kann, ist das eine Prüfung durchgeführt wird, ob eine bestimmte Operation durchgeführt werden kann. Wir vermuten, wir wissen! Ein Design Pattern findet hierbei Anwendung: Circuit Breaker (http://en.wikipedia.org/wiki/Circuit_breaker_design_pattern).