Domain Driven Design (DDD) ist eine Herangehensweise an Software-Design, die radikal die Fachlichkeit, die Domäne, in das Zentrum der Software stellt. Das Ziel ist hierbei, jegliche technischen Ausgestaltungen und Besonderheiten möglichst weit in die Peripherie zu verlagern, um nicht durch zu verfrühte technische Überlegungen das Fachmodell in eine bestimmte Richtung zu treiben.
Vorgestellt wurde DDD2003 von Eric Evans in seinem Buch „Domain-Driven Design – Tackling Complexity in the Heart of Software“. Ziel von DDD ist es, wohlstrukturierte Software-Systeme zu modellieren, die sich nicht nach kurzer Zeit in Spaghetti-Code verwandeln, bzw. in einen big ball of mud, wie es von der DDD community gerne genannt wird. DDD soll also letztendlich zu gut wartbarer und stabiler Software führen.
Ein zentrales Konzept in einer DDD-Modellierung sind sogenannte bounded contexts. Hierbei handelt es sich um semantisch motivierte Abgrenzungen in der Domäne, weswegen man sie auch Subdomänen nennt. Innerhalb eines bounded contexts gibt es eine ubiquitous language, also eine allgemeingültige Sprache. Beim DDD ist also eine der wichtigsten Aufgaben, eine ebensolche allgemeingültige Sprache herauszuarbeiten. Es soll ganz eindeutig klar sein, was mit einem bestimmten Begriff in der Domäne gemeint ist und ein Objekt in der Domäne sollte auch nur einen eindeutigen Bezeichner haben und nicht durch mehrere äquivalente Begriffe bezeichnet werden. Die allgemeingültige Sprache soll hierbei sowohl von den Fachexperten als auch von den Software-Entwicklern gemeinsam gesprochen werden, soll sich also sowohl in Konzeptionsdokumenten als auch im Quellcode wiederfinden. Eine praktische Methode zur Herausarbeitung einer allgemeingültigen Sprache ist hierbei das Event Storming, worauf später näher eingegangen wird.
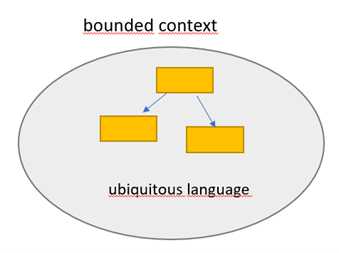
Die allgemeingültige Sprache gilt nur innerhalb eines einzelnen bounded contexts und jeder bounded context hat seine eigene allgemeingültige Sprache. Es kann also durchaus vorkommen, dass ein Begriff in mehreren bounded contexts vorkommt, dort jeweils aber ganz unterschiedliche Bedeutungen hat. Der Begriff Platz hätte zum Beispiel in einem bounded context Büroplatzreservierung die Bedeutung „Arbeitsplatz, Tisch“, im bounded context Städtebau würde er aber wohl eher einen „öffentlichen Platz“ bezeichnen. Diese Abgrenzung ist sehr wichtig, um die jeweiligen Subdomänen, bzw. bounded contexts, sauber zu halten. Jeder bounded context weiß nur über seine eigenen Interna Bescheid und muss und soll nichts darüber wissen, was seine einzelnen Begriffe in anderen bounded contexts bedeuten könnten. Es wird auch vermieden, dass Begriffe unnötig lang werden, indem man ganz genau ausdifferenziert, um welche Art es sich hier handelt. Innerhalb eines gegebenen bounded contexts ist es eindeutig, was mit Platz gemeint ist.
Man kann verschiedene Subdomänen in einem Softwareprojekt unterscheiden, die sich dadurch unterscheiden, wie essenziell sie für das von der Software zu lösende Problem sind. Wichtig ist es, vor allen Dingen die Kerndomäne herauszuarbeiten, also genau die Subdomäne in der die zentralen Businessprozesse des jeweiligen Programmes stattfinden. In die Konzeption und Implementierung dieser Domäne sollte die meiste Zeit und Arbeit fließen. Subdomänen, die die Kerndomäne nur unterstützen können hierbei weniger im Fokus stehen, oder wenn sie generisch genug sind, durch die Nutzung von bestehenden Bibliotheken ersetzt werden. Es gibt verschiedene Arten, wie bounded contexts miteinander kommunizieren können. Dies nennt man das context mapping und man kann es sich wie die Übersetzung zwischen zwei Sprachen vorstellen. Die einfachste Methode ist die Kommunikation über einen shared kernel, also einen gemeinsamen Kern. Hierbei teilen sich die beiden bounded contexts einen Teil ihrer Domäne.

Diese Interaktion ist sehr einfach zu implementieren, da man keine zusätzlichen Mapping-Schichten braucht, man könnte sagen, die beiden bounded contexts sprechen dieselbe Sprache und brauchen keinen Dolmetscher, wenn sie sich unterhalten. Diese Interaktion weist allerdings eine hohe Kopplung der Systeme auf und führt letztendlich zu schlechterer Wartbarkeit und die Gefahr, dass das System sich irgendwann in einen big ball of mud verwandelt ist, sehr groß.
Am saubersten ist die Interaktion von zwei Subdomänen über eine published language, also eine veröffentlichte Sprache.
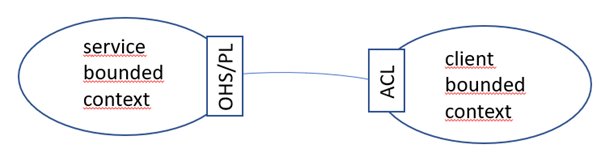
Der service bounded context bietet einen Dienst an und teilt mit, in welcher Sprache man eine Anfrage an ihn richten kann. Der client bounded context kann dann eine Anfrage an den service bounded context genau in dieser Sprache richten. Wahlweise kann man als zusätzliche Sicherheit einen anti corruption layer (ACL) im client bounded context dazwischenschalten, der als Zwischenmodell zwischen dem service Modell und dem client Modell fungiert und somit die Gefahr minimiert, dass ein evtl. unsauberes service Modell langsam das client Modell „infiziert“. Dies ist vor allen Dingen ratsam, wenn der service bounded context kein sauberes, kleines, abgekapseltes DDD-System ist, sondern ein big ball of mud Legacy-System. Ein ACL vergrößert aber die Komplexität des Systems und sollte somit mit Bedacht eingesetzt werden.
Im DDD wird zwischen zwei verschiedenen Arten von Objekten unterschieden: entities (Entitäten) und value objects (Wertobjekte). Im Deutschen werden hier aber auch meist die englischen Begriffe verwendet. Entities sind Objekte, die eine eigene eindeutige Identität haben. Normalerweise sind sie veränderbar, dies ist aber keine notwendige Bedingung. Die Gleichheit von zwei Entitäten ergibt sich nicht über die Gleichheit ihrer Attribute, sondern über die Gleichheit ihrer eindeutigen Identität. Im bounded context einer Büroplatzreservierung wäre z.B. ein Büroplatz eine entity. Die Büroplätze kann man durchnummerieren, sie haben also eine eindeutige Identität.
Value objects hingegen enthalten hingegen, wie der Name bereits vermuten lässt lediglich Werte. Sie sind unveränderbar und haben keine eindeutige Identität. Die Gleichheit zweier value objects ergibt sich über die Gleichheit ihrer Attribute. Die eindeutigen Identitäten von entities werden häufig als value object modelliert, so dass z.B. die Büroplatznummer ein value object im bounded context Büroplatzreservierung wäre.
In einem komplexeren DDD-System hat man es meist nicht mit einzelnen entities und value objects zu tun, sondern mit untereinander verknüpften Objekten, sogenannten Aggregaten. Ein Aggregat besteht aus einer entity, der sogenannten Wurzel des Aggregates und mehreren entites und value objects, die mit dieser Aggregatswurzel zusammenhängen. Aggregate sind nach außen gekapselt und ein Zugriff auf ein Aggregat soll nur über die Wurzel erfolgen.
Architektur:
DDD ist ein Framework, oder man könnte auch sagen ein Paradigma, um Software zu designen, schreibt aber keine konkrete Software-Architektur vor. Evans schlägt in seinem Buch eine klassische Schichten-Struktur (layered architecture) vor.
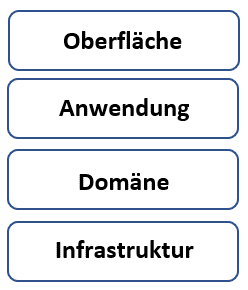
Die Infrastrukturschicht enthält klassischerweise die Persistenzschicht zum Beispiel in Form einer Datenbank, aber auch die Anbindung an ein Messaging-System findet in dieser Schicht statt. Die Domäne enthält die eigentliche Businesslogik. Die Anwendungsschicht enthält zum Beispiel die Koordinierung von einzelnen Bereichen der Businesslogik, enthält aber selbst keine Businesslogik. In der Oberflächenschicht werden Daten dargestellt und Eingaben der Anwender entgegengenommen.
Dass Evans bei einem mit DDD designten System an eine Schichtenarchitektur denkt, ist sicherlich auch der Zeit geschuldet. Mittlerweile gibt es hier aber neuere Architekturansätze, die meiner Meinung nach deutlich mehr dem Grundgedanken von DDD entsprechen, zum Beispiel die Hexagonale Architektur. Anstelle von Schichten befindet sich hier die Domänenlogik in der Mitte der Software-Architektur und alle anderen Aufgaben sind um dieses Zentrum als Adapter angeordnet. Verbunden werden diese Adapter mit dem Kern über Ports. Man nennt diese Architektur deshalb auch Ports and Adapters. Hierbei wird auch architekturell widergespiegelt, dass bei einem mit DDD modellierten System die Domäne im Zentrum steht.
Event Storming:
Event Storming ist ein von Alberto Brandolini 2013 vorgestelltes Workshop-Format, um eine Domäne zu erkunden. Die Domäne wird hierbei ausgehend von sogenannten Domänen-Events analysiert und beschrieben, es ist also ein Brainstorming von Domänen-Events. An einem solchen Workshop sollen sowohl die Domänen-Experten (ohne tiefere technische Kenntnisse) als auch die Technik-Experten teilnehmen. Ein solches Format ist also bestens geeignet, um gemeinsam eine allgemeingültige Sprache für die Domäne herauszuarbeiten.
Für ein Event Storming benötigt man eine große, freie Wand und viele Post Its in verschiedenen Farben.
- Zuerst klebt jeder Teilnehmer in einer bestimmten Farbe alle Domänen-Events an die Wand, die ihm zu der Domäne einfallen. Ein Domänen-Event ist etwas, was in der Domäne passiert ist, z.B. „Ein Büroplatz wurde reserviert“. Sie werden also immer in der Vergangenheit und möglichst auch im Passiv formuliert. Anschließend werden die Domänen-Events von allen Teilnehmern gruppiert und chronologisch sortiert. Hierbei wird es viele ähnliche Domänen-Events geben, die fast identisch sind, sich aber in der Formulierung unterscheiden. Genau hier kommt es dann zu sehr fruchtbaren Diskussionen, welche der Formulierungen gewählt werden soll, oder ob eine ganz neue Formulierung gewählt werden soll.
Heißt es z.B. besser „Ein Büroplatz wurde reserviert.“ oder „Eine Tischreservierung wurde angefordert.“? Wird eine Reservierung automatisch vorgenommen, oder fragt man eine Reservierung nur an und sie muss von irgendeiner Instanz genehmigt werden? Handelt es sich nur um Tische, oder gibt es auch andere Büroplätze? Diese Diskussionen über Begrifflichkeiten führen dazu, dass man sich über die genauen Details der Domäne unterhält und zu einem gemeinsamen Verständnis kommt.
- Danach wird zu jedem Domänen-Event ein weiterer Zettel geklebt, der die Aktion bezeichnet, die zu dem Domänen-Event geführt hat, also z.B. „Reserviere einen Büroplatz“. Die Formulierung sollte natürlich zu den Domänen-Events passen. In vielen Fällen sind diese Aktionen trivial, es kann aber auch vorkommen, dass eine Aktion z.B. mehrere Domänen-Events triggert.
- Danach wird zu allen Domänen-Events und ihren dazugehörigen Aktionen ein weiterer Zettel geklebt, der angibt, in welcher Entity dieses Domänen-Event stattfindet. Hier gibt es in unserem Beispiel verschiedene Möglichkeiten. Es könnte hier z.B. eine Mitarbeiter entity sein. Man könnte aber auch von einer anderen Seite auf das Problem schauen und diese Domänenevents in einer Büroplatz entity modellieren. Hier ist keine der beiden Möglichkeiten falsch, aber eine Möglichkeit könnte unter Umständen besser zur Aufgabenstellung der zu entwickelnden Anwendung passen. Dies gilt es im Event Storming zu erörtern.
- In einem letzten Schritt wird zu jeder Aktion dazugeschrieben, welche Informationen, beziehungsweise Parameter diese Aktion benötigt, z.B. in welchem Zeitraum der Büroplatz reserviert werden soll.
Nach einem solchen Event Storming kann man die Businesslogik einer Domäne direkt in einer beliebigen Programmiersprache implementieren. Alle entities, value objects, Bezeichner von Methoden, Parameter usw. sind bereits im Prozess des event stormings modelliert und diskutiert worden und entsprechen der gemeinsam gesprochenen Sprache von Technik- und Domänen-Experten. Somit hat man eine Domänenlogik implementiert, die fast komplett frei von technischen Spezifitäten ist (wie z.B. Datenbanken, Messaging-Systeme, Frontend-Technologien usw.). Diese Businesslogik kann man dann perfekt als Kern einer Anwendung im Sinne der hexagonalen Architektur verwenden und darum als Adapter die geforderten technischen Ausimplementierungen anlegen.
Das Event Storming ist ein iterativer Prozess und man kann ein und dieselbe Domäne zu mehreren Zeitpunkten in der Programmentwicklung wiederholen, weil sich im Laufe der Zeit und der Auseinandersetzung mit der Domäne ein vertieftes Verständnis entwickelt, weswegen man die Modellierung mit jedem Event Storming immer weiter verfeinern kann.
Zum Weiterlesen:
- Eric Evans – „Domain-Driven Design – Tackling Complexity in the Heart of Software“: Das ausführliche Hauptwerk zu DDD
- Vaughn Vernon – „Domain-Driven Design Distilled“: Eine kurze, gut verständliche Zusammenfassung der grundlegenden Konzepte von DDD
- http://ziobrando.blogspot.com/2013/11/introducing-event-storming.html
Blogbeitrag zum Event Storming. Hierzu gibt es leider bisher noch keine dedizierten Bücher - https://www.maibornwolff.de/know-how/ddd-architekturen-im-vergleich/
Beschreibung unterschiedlicher Software-Architekturen in Verbindung mit DDD