For my current project I’ve been forced to work with Lucene. Who’s that?
It’s an open source library for information retrieval. It’s good for finding information in really big data. So if you want to find sth. fast in the archives of the National Library, you might want to use Lucene.
Why is it so fast? As a reader of this blog, you know how a database works to find information. It looks into the first record of a table, compares it, into the second, compares it etc. It’s pretty obvious, that this is slow.
So Lucene does something different. Instead of going through each single record of your table, it uses an inverted index. This index maps keywords to the position in the data set, e.g. it says, that the word “computer” is to be found in the documents 12345, 55555 and 99999. Instead of going through document 1 to 99999, like a database does.
Because I was totally unfamiliar with Lucene at the time, I wanted to write sth. “real” with Lucene – a simple File finder, where you can search files on a hard disk. It’s only a little bit more sophisticated than ‘Hello World’, but you might find it useful, if you want to get your hands dirty.
FileFinder
Click here: Launch demo
You can download the sources here
Screenshot: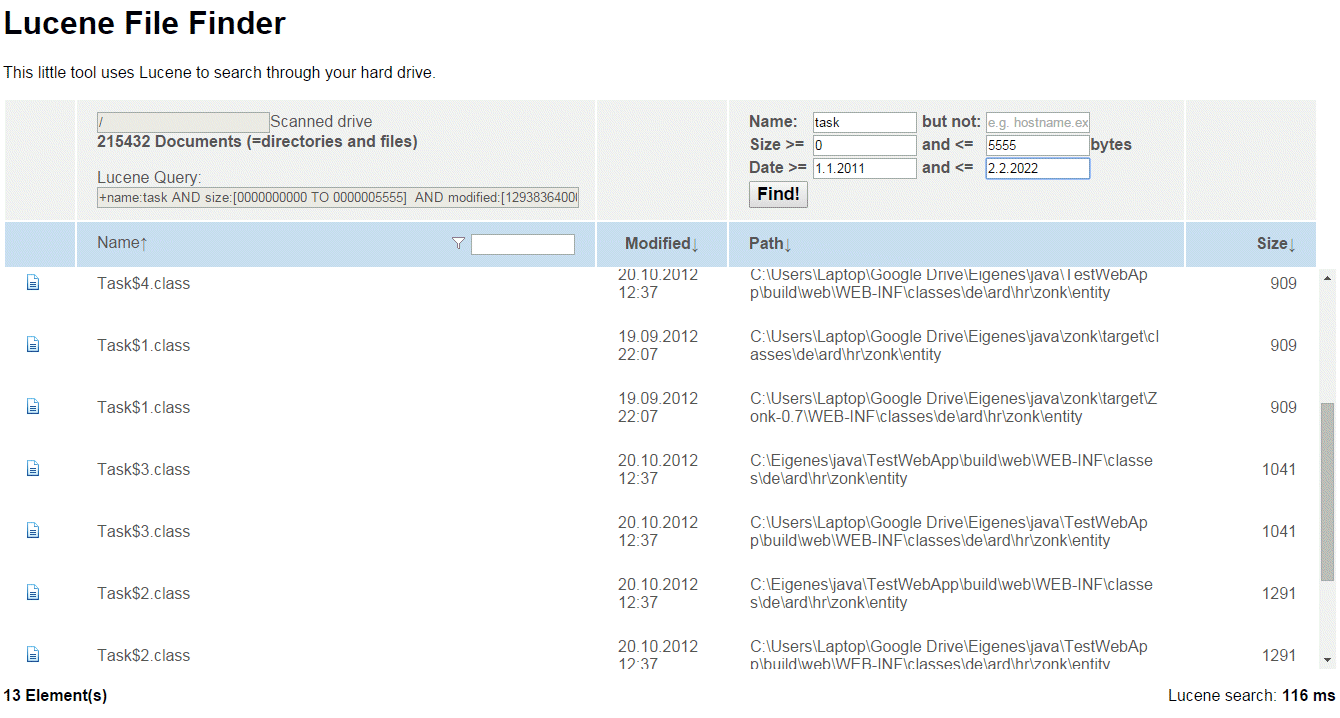
About this little app:
The first thing that needs to be done is to create the index, i.e. store information about your files in the index of Lucene. After that, you can query the index, much in the way you do it with SQL.
A lucene query might look like that:
+name:task AND size:[0000000000 TO 0000005555] AND modified:[1293836400000 TO 1643756400000]
The query is easy to read: Look for a file that contains ‘task’, has a size between 0 and 5555 bytes and is modified between those two long values (where long represents a date).
Feel free to comment on this article.